Extended Tutorial
The extended tutorial builds on the basic tutorial, using an additional set of stages to perform some data transformations and write to the Trash destination. We'll also use data preview to test stage configuration.
You can write to a real destination instead of the Trash destination. The Trash destination allows you to run the pipeline without writing to a real destination system.
- Configure a Field Type Converter processor to convert field types.
- Manipulate data with the Expression Evaluator processor.
- Use data preview to test and update pipeline configuration.
- Complete the pipeline with the placeholder Trash destination.
- Reset the origin and run the extended pipeline.
Convert Types with a Field Type Converter
Since the sample data is read from a file, the fields are all strings. Let's use a Field Type Converter processor to convert some data types.
- Add a Field Type Converter processor to the canvas.
-
To route all data from the pipeline through the new stage, connect the Field
Masker and the Expression Evaluator processors to it, as shown:
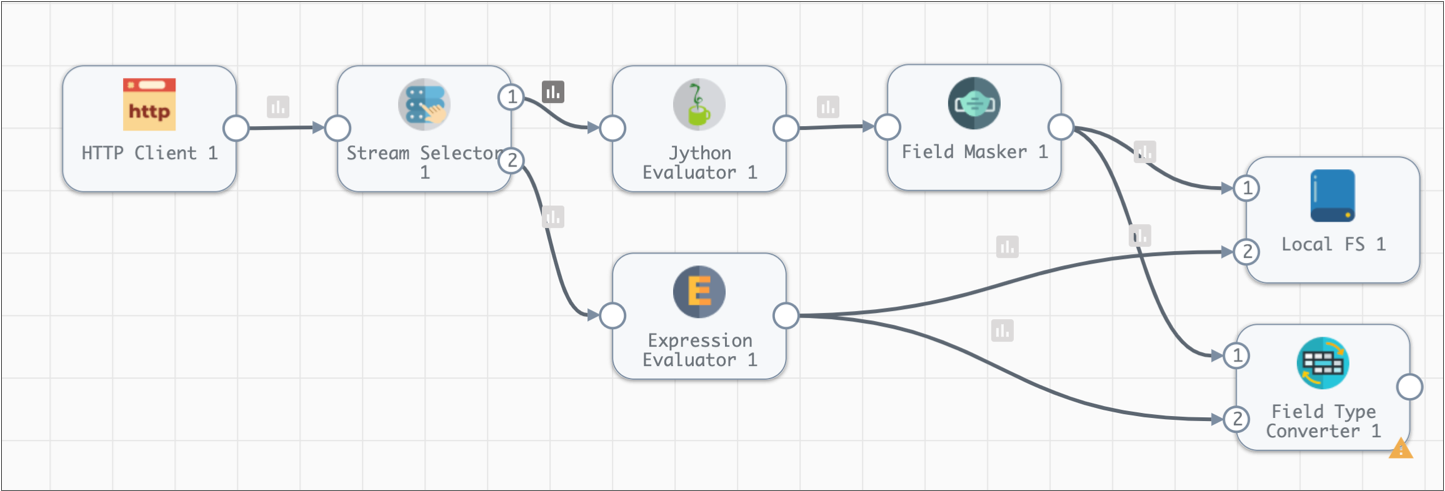
- Click the Conversions tab.
- Select By Data Type for Conversion Method.
-
Convert fields with datetime data to Datetime as follows:
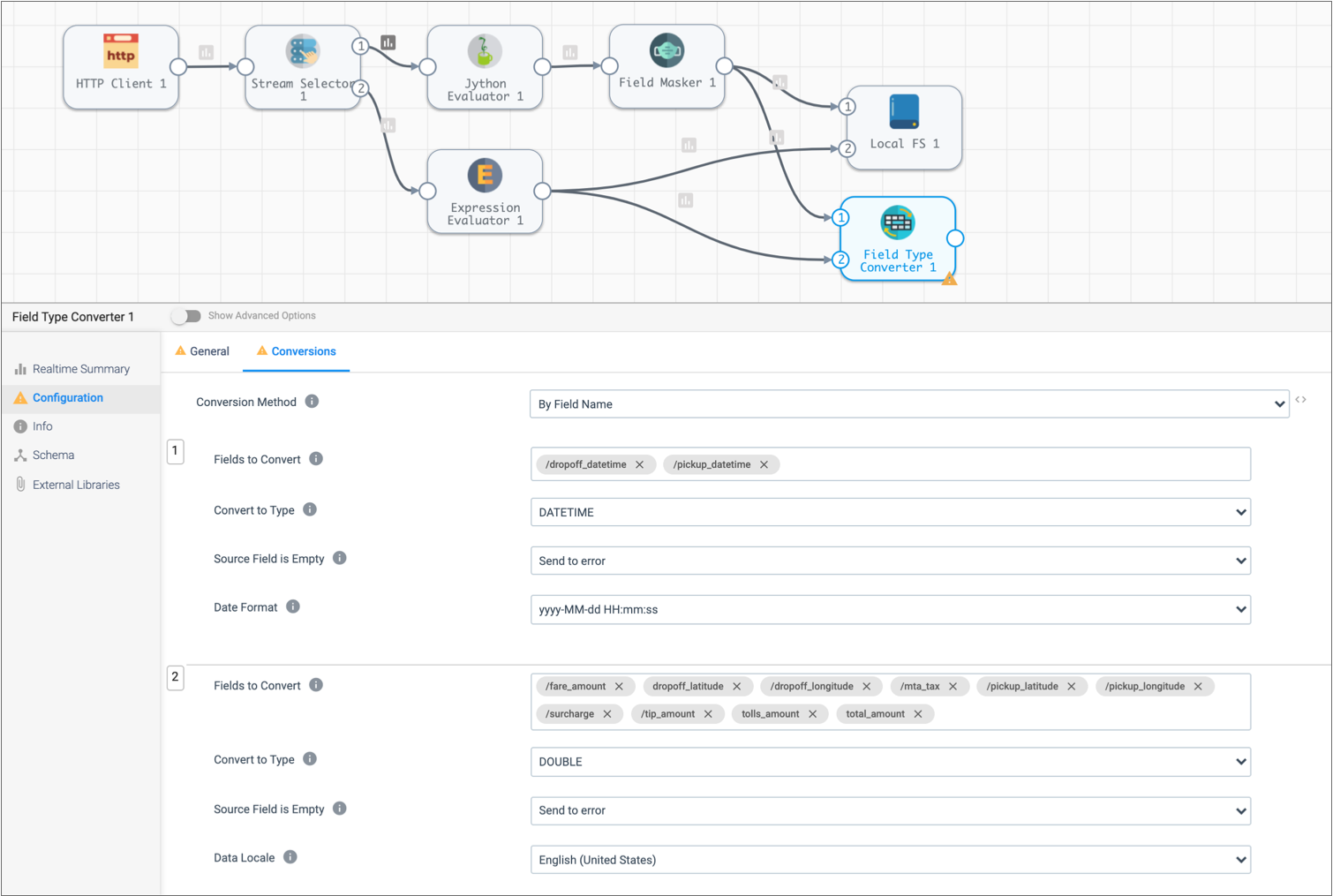
Field Type Converter Property Datetime Conversion Fields to Convert Click in the field. From the list of fields, select the following fields: /dropoff_datetime- /
pickup_datetime
Convert to Type DATETIME Date Format Date format used by the data: yyyy-MM-dd HH:mm:ss.
-
To convert fields that contain monetary information to Double, click the
Add icon and configure the properties as follows.
Use the defaults for properties that aren't listed:
Field Type Converter Property Double Conversion Fields to Convert Click in the field and select the following fields: /fare_amount/dropoff_latitude/dropoff_longitude- /
mta_tax /pickup_latitude/pickup_longitude/surcharge/tip_amount/tolls_amount/total_amount
If a field doesn't display in a list, you can type in the field name and use the Tab or Enter key to complete the action.
Convert to Type DOUBLE
Manipulate Data with the Expression Evaluator
Now we'll use an Expression Evaluator processor to create pickup and dropoff location fields that merge the latitude and longitude details. We'll also calculate the basic trip revenue by subtracting the tip from the total fare.
- Add an Expression Evaluator processor to the canvas and connect it to the Field Type Converter processor.
-
On the Expressions tab, click the
Add icon, and then enter the following information to
generate the pickup and dropoff location data:
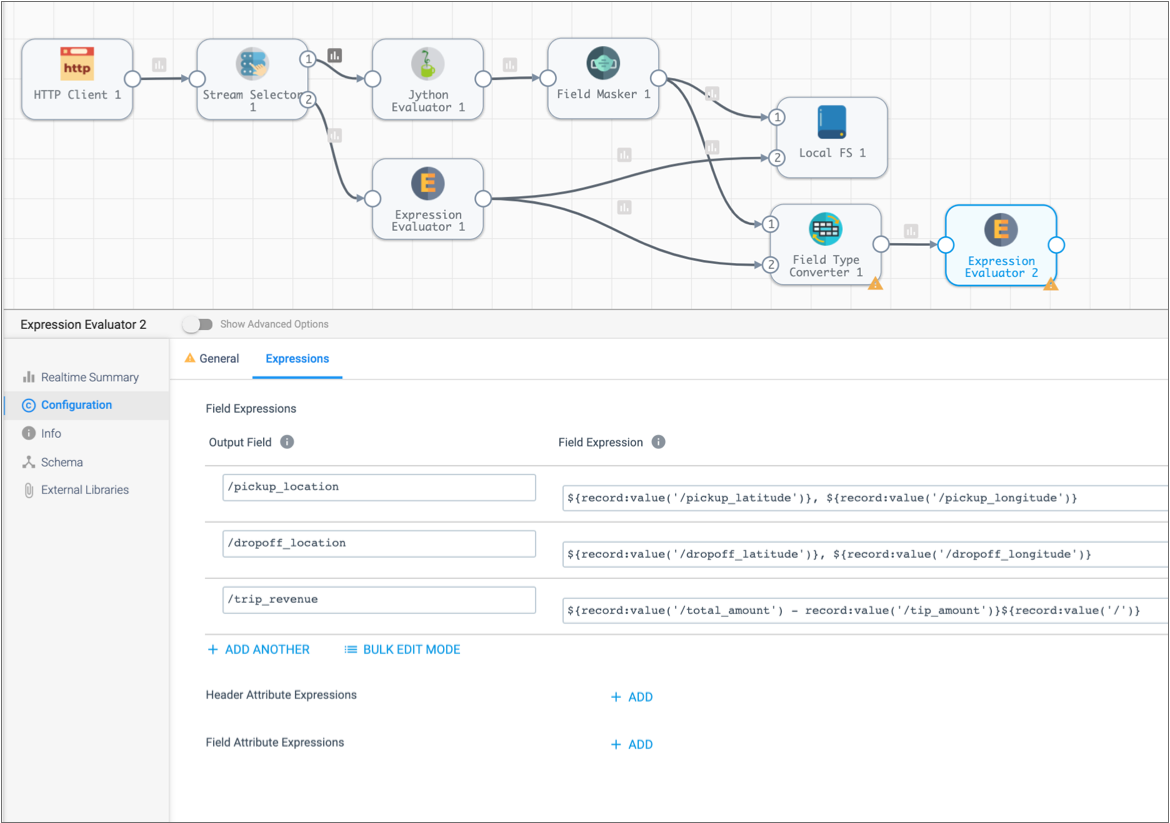
Output Field Expression /pickup_location${record:value('/pickup_latitude')}, ${record:value('/pickup_longitude')}/dropoff_location${record:value('/dropoff_latitude')}, ${record:value('/dropoff_longitude')}These expressions return the data from the two fields in the following format:<latitude>, <longitude>. -
To add another expression, click the Add icon and enter
the following information to subtract the tip from the total fare:
Output Field Expression /trip_revenue${record:value('/total_amount') - record:value('/tip_amount')} -
Since we don't need to change header or field attributes, use the
Subtract icon (
 ) to delete both expressions.
) to delete both expressions.
Here's the Expression Evaluator processor configuration in the extended pipeline:
Preview and Edit the Pipeline
The extended tutorial is almost done, so let's use data preview to see how different stages transform data. We'll make some configuration changes and do some testing by editing preview data.
To preview the pipeline, click the Preview icon: ![]() .
.
- Field Masker Processor
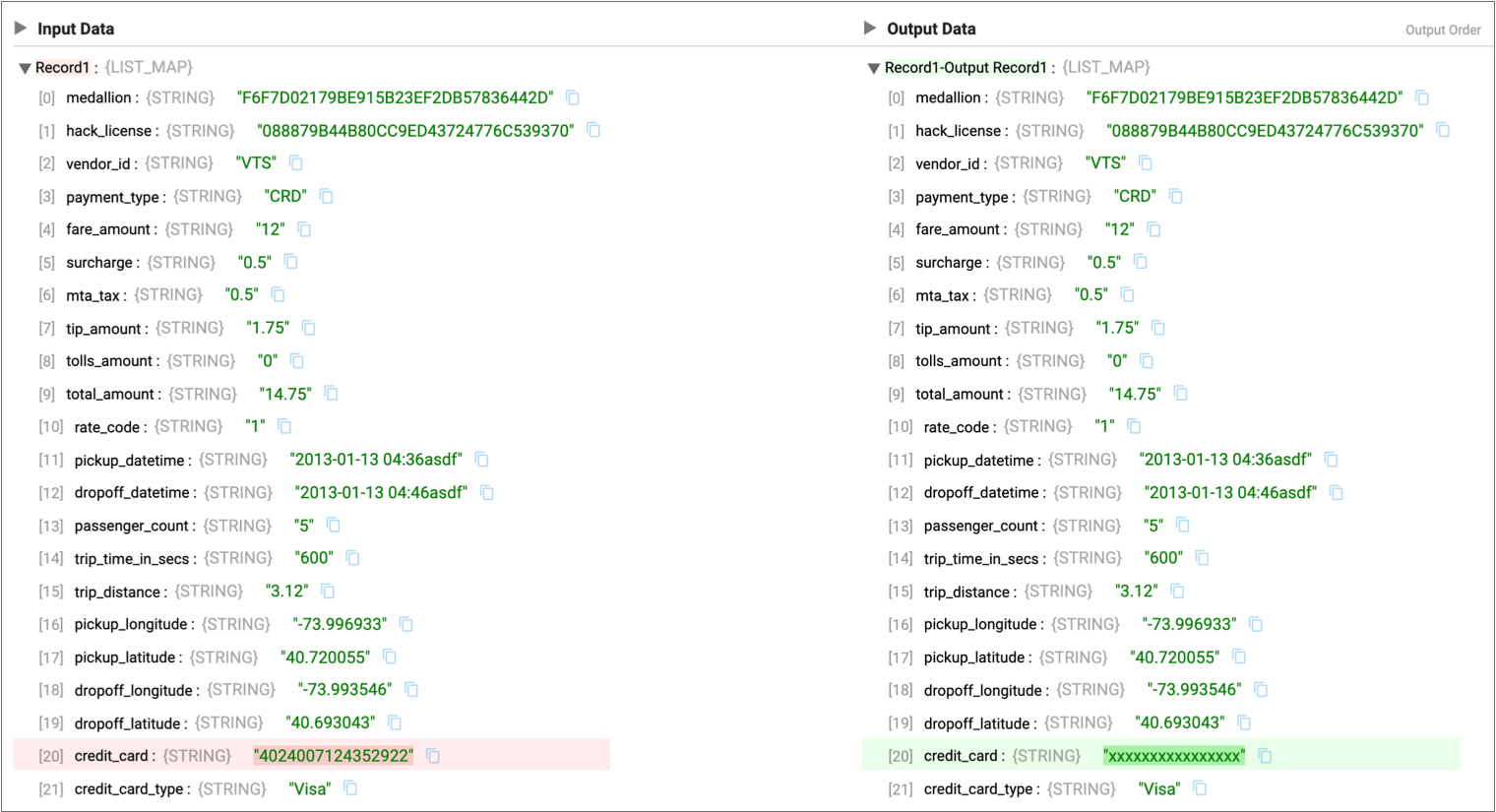
- Let's see how the Field Masker processor masks credit card numbers and change the mask that the stage uses.
- Say we want to mask the whole credit card number. To review the stage configuration
and try a different option:
- Under Preview Stage on the left side of the Preview panel,
select the Stage Configuration icon:
 .
. - Click the Mask tab.
- Change the Mask Type to Variable Length to mask all numbers while showing how many numbers there are in the data.
- To view the results of this change, click the Run with
Changes icon:
 .
. - In the Preview panel, select the Records tab to view the
updated preview records:
 .
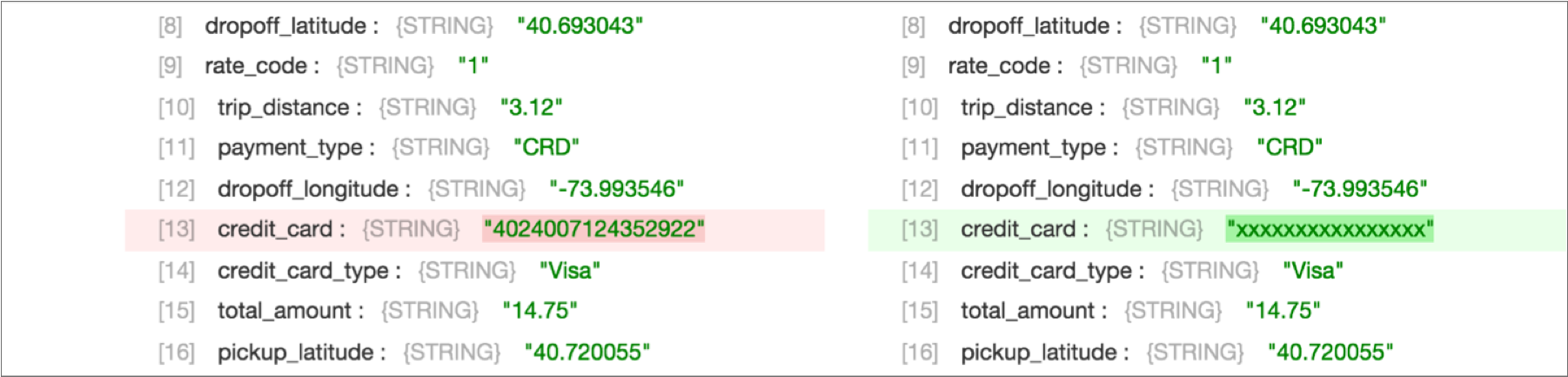
. - Expand an output record, and notice how the entire credit card number is now
masked:
- Under Preview Stage on the left side of the Preview panel,
select the Stage Configuration icon:
- Field Type Converter Processor
- The Field Type Converter changes the data type of a few fields. We'll take a look at
that stage and try changing stage configuration.
- Select Field Type Converter. On the left side of the panel,
click Advanced Properties: .
Notice the On Record Error property is set to Send
to Error.
This means error records are sent to the pipeline for error handling. We configured the pipeline to write all error records to file, so error records from this stage are written to file.
You can configure this property to stop the pipeline on encountering an error record or to discard error records.
- To see how it looks when you discard errors, set On Record Error to Discard, and then click the Run with Changes icon.
- In the Preview panel, click the Records icon.
Notice the first record is discarded without notice of the error that occurred.
- We prefer to keep error records, so go back to the Stage Configuration tab and change On Record Error back to Send to Error.
- Select Field Type Converter. On the left side of the panel,
click Advanced Properties:
- Second Expression Evaluator Processor
- The second Expression Evaluator processor manipulates data. Let's try editing the
preview data:
- Select the Expression Evaluator, then click the
Records icon and expand the first input and output record.
Notice the fields created by the stage -
dropoff_location,pickup_locationandtrip_revenue- are highlighted in green.Though it isn't necessary for these calculations, let's see how you can edit preview data to test stage configuration:
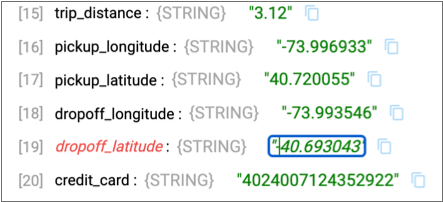
- In the first input record, in the Output Data column, click on the
dropoff_latitudedata, 40.693043, add a negative sign before the data. Press Enter or click outside the data.As shown below, the field name for the edited input data becomes red and the data is italicized to indicate a change.
- To test the change, click the Run with Changes icon.
You should see this change in the downstream stages.
You can also see how this functionality might come in handy when you want to test some cases that didn't come up in the preview data.
- To revert that change, click the Revert Data Changes icon:
 .
.This icon reverts changes to preview data.
Note: Revert Data Changes does not revert changes to stage or pipeline configuration. Manually revert configuration changes that you don't want to keep, as we did earlier in the tutorial.
- Select the Expression Evaluator, then click the
Records icon and expand the first input and output record.
When you're done exploring the preview data, click Close Preview.
Write to Trash
To wrap up the extended tutorial, let's use the Trash destination as a temporary placeholder.
The Trash destination deletes any records that pass to it. This allows you to test a pipeline without writing data to a production system.
If you prefer, you can use the Local FS destination to write to file as we did earlier in the tutorial, or you can use another destination to write to a development destination system available to you.
The Trash destination requires no configuration, so just add it to the canvas and connect the Expression Evaluator processor to it:
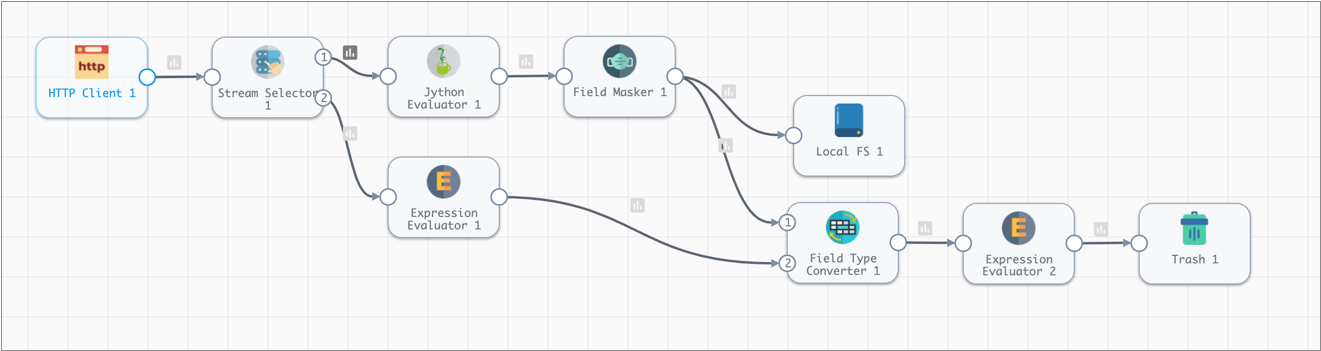
Run the Extended Pipeline
Now that the extended pipeline is complete, let's reset the origin and perform a test run the draft pipeline again.
Reset the origin when you want Data Collector to process all available data instead of processing data from the last-saved offset. Not all origins can be reset, but you can reset the origin for the HTTP Client origin.
To reset the origin and perform a test run, click Test Run > Reset Origin and Start.
The UI enters Monitor mode and the data alert triggers again. You'll see some error records in the Jython Evaluator and the Field Type Converter processors.For each stage, you can see the error messages for latest error records.
To look at all the error records, you can review the error record files in the directory that you specified. Error records are written in the Data Collector Record data format so you can create an error pipeline to process error records.
That's it for this tutorial. Hope you found it helpful!