MLeap Evaluator
The MLeap Evaluator processor uses a machine learning model stored in an MLeap bundle to generate evaluations, scoring, or classifications of data.
With the MLeap Evaluator processor, you can create pipelines that produce data-driven insights in real time. For example, you can design pipelines that detect fraudulent transactions or that perform natural language processing as data passes through the pipeline.
To use the MLeap Evaluator processor, you first build and train the model with your preferred machine learning technology. You then export the trained model to an MLeap bundle and save that file on the Data Collector machine that runs the pipeline.
When you configure the MLeap Evaluator processor, you define the path to the saved MLeap bundle stored on the Data Collector machine. You also define mappings between fields in the record and input fields in the model, and you define the model fields to output and the record field to store the model output.
Prerequisites
- Build and train a machine learning model with your preferred machine learning technology.
- Export the trained model to an MLeap bundle. For more information, see the MLeap documentation.
- Save the bundle file on the Data Collector machine that runs the pipeline. Store the model directory in the Data Collector resources directory, $SDC_RESOURCES.
MLeap Model as a Microservice
External clients can use a model in an MLeap bundle to perform computations when you include an MLeap Evaluator processor in a microservice pipeline.
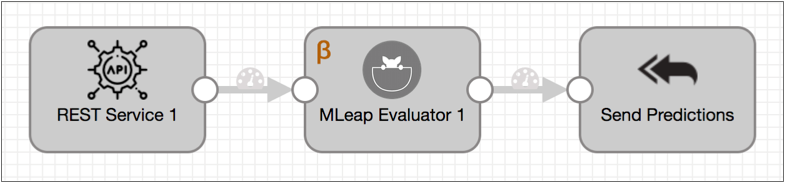
For example, in the following microservice pipeline, a REST API client sends a request with input data to the REST Service origin. The MLeap Evaluator processor uses a machine learning model to generate predictions and passes records that contain those predictions from the model to the Send Response to Origin destination, labeled Send Predictions, which sends the records back to the REST Service origin. The origin then transmits JSON-formatted responses back to the originating REST API client.
Example: Airbnb Model
- airbnb.model.lr.zip – Uses a linear regression model.
- airbnb.model.rf.zip – Uses a random forest regression model.
{
"security_deposit": 50.0,
"bedrooms": 3.0,
"instant_bookable": "1.0",
"room_type": "Entire home/apt",
"state": "NY",
"cancellation_policy": "strict",
"square_feet": 1250.0,
"number_of_reviews": 56.0,
"extra_people": 2.0,
"bathrooms": 2.0,
"host_is_superhost": "1.0",
"review_scores_rating": 90.0,
"cleaning_fee": 30.0
}And the model generates a predicted price of $218.28 in the
price_prediction field.
To include this model in a pipeline, save the MLeap bundle on the Data Collector machine, add the MLeap Evaluator processor to the pipeline, and then configure the processor to use the MLeap bundle and to map the required input fields and generated output field to fields in the record. The following image shows the processor configuration:
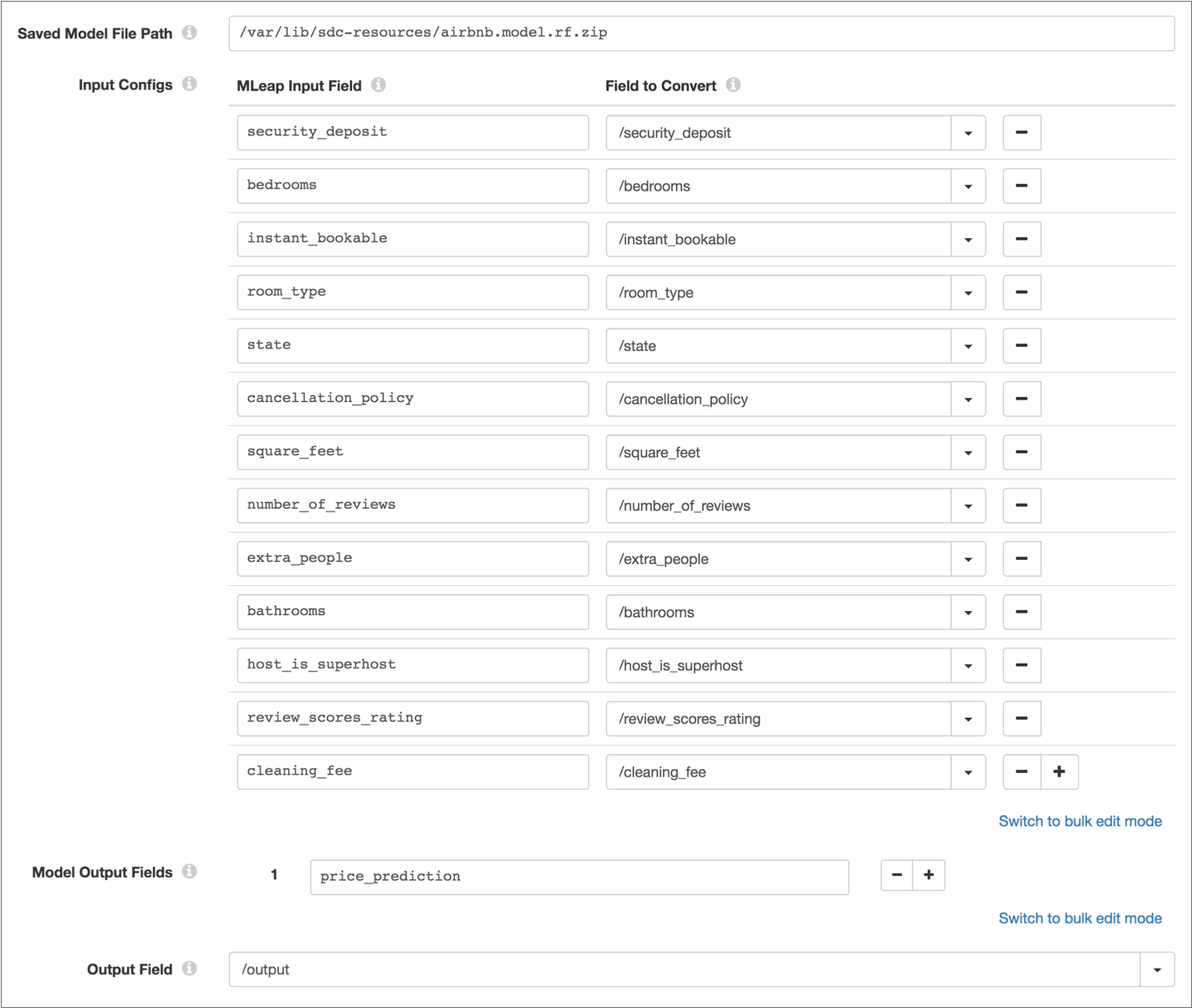
Configuring an MLeap Evaluator Processor
-
In the Properties panel, on the General tab, configure the
following properties:
General Property Description Name Stage name. Description Optional description. Required Fields Fields that must include data for the record to be passed into the stage. Tip: You might include fields that the stage uses.Records that do not include all required fields are processed based on the error handling configured for the pipeline.
Preconditions Conditions that must evaluate to TRUE to allow a record to enter the stage for processing. Click Add to create additional preconditions. Records that do not meet all preconditions are processed based on the error handling configured for the stage.
On Record Error Error record handling for the stage: - Discard - Discards the record.
- Send to Error - Sends the record to the pipeline for error handling.
- Stop Pipeline - Stops the pipeline.
-
On the MLeap tab, configure the following
properties:
MLeap Property Description Saved Model File Path Path to the saved MLeap bundle on the Data Collector machine. Specify either an absolute path or the path relative to the Data Collector resources directory. For example, if you saved a bundle named pricing.model.zip in the Data Collector resources directory /var/lib/sdc-resources, then enter either of the following paths:- /var/lib/sdc-resources/pricing.model.zip
- pricing.model.zip
Input Configs Mapping of input fields in the machine learning model to fields in the record. For each mapping, enter: - MLeap Input Field – An input field in the model stored in the MLeap bundle.
- Field to Convert – The corresponding field in the record, specified as a path.
Model Output Fields Output fields in the model to return to the pipeline. Output Field List-map field that stores model output in the record. Specify as a path.