Pipeline Processing on Spark
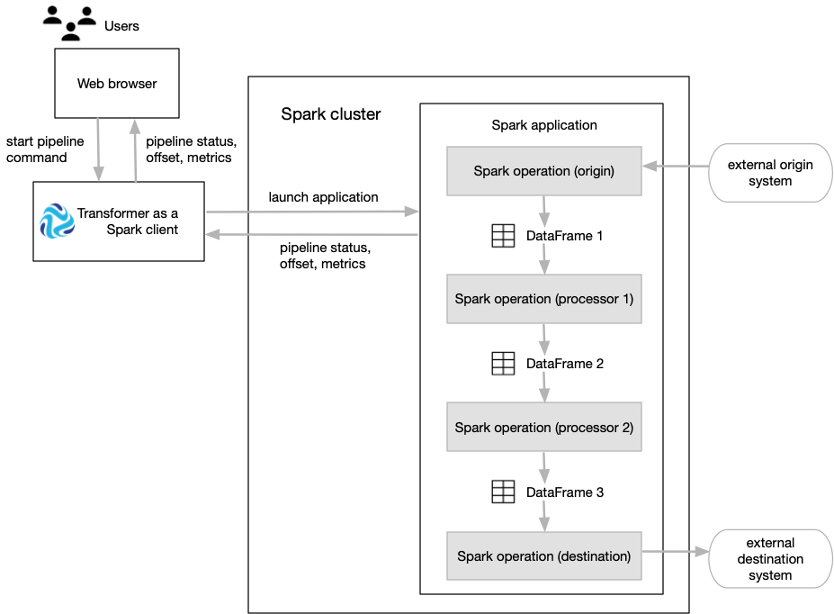
Transformer functions as a Spark client that launches distributed Spark applications.
When you start a pipeline on a Hadoop cluster, Transformer uses the Spark Launcher API to launch a Spark application. When you start a pipeline on a Databricks cluster, Transformer uses the Databricks REST API to run a Databricks job which launches a Spark application.
Transformer passes the pipeline definition in JSON format as an application argument. Spark runs
the application just as it runs any other application, distributing the processing
across nodes in the cluster.
Note: To get started with Transformer in a development environment, you can simply install both Transformer and Spark on the same machine and run Spark locally on that machine. In this
case, Spark runs each application on the single machine.
Each pipeline stage represents a Spark operation:
- The Spark operation for an origin reads data from the origin system in a batch. The origin represents the data as a Spark DataFrame and passes the DataFrame to the next operation.
- The Spark operation for each processor receives a DataFrame, operates on that data, and then returns a new DataFrame that is passed to the next operation.
- The Spark operation for a destination receives a DataFrame, converts the DataFrame to the specified data format such as Avro, Delimited, JSON, or Parquet, and then writes the converted data to the destination system.
As the Spark application runs, you use the Transformer UI to monitor the progress of the pipeline and troubleshoot any errors. When you stop the pipeline, Transformer stops the Spark application.
The following image shows how Transformer submits a pipeline to Spark as an application and how Spark runs that application: