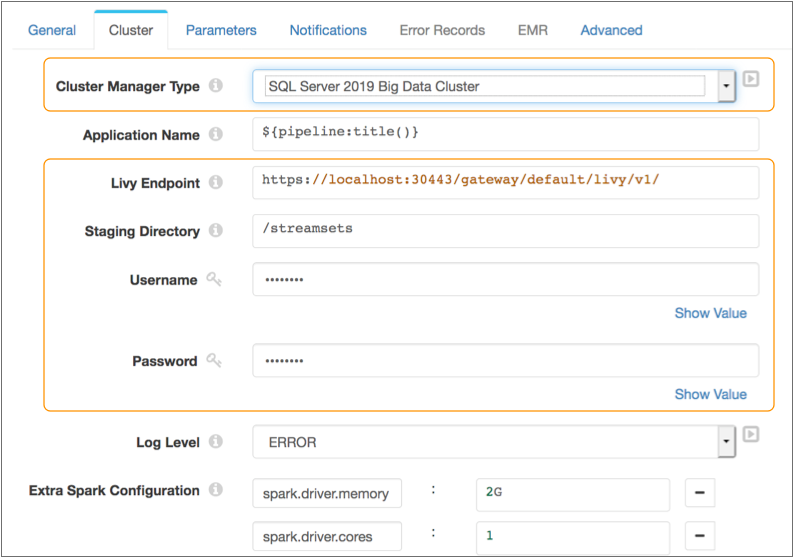
You can run Transformer pipelines using Spark deployed on (BDC). Transformer supports . uses Apache Livy to submit Spark jobs.
You specify the Livy endpoint, as well as the user name and password to access the cluster through the endpoint.
You also define the staging directory within the cluster to store the StreamSets libraries and resources needed to run the pipeline.
mssql-mleap-lib-assembly-1.0.jar file from
the following HDFS ZIP file: /system/spark/spark_libs.zip. This
issue should be fixed in the next release.The following image displays a pipeline configured to run using Spark deployed on at the specified Livy endpoint:
StreamSets provides a quick start deployment script that enables you to easily try using as a cluster manager for Transformer pipelines without additional configuration. For example, you might use the script to try using as a cluster manager but aren't ready to upgrade to Transformer 3.13.x or later.