Hadoop YARN
You can run Transformer pipelines using Spark deployed on a Hadoop YARN cluster. Transformer supports several distributions of Hadoop YARN. For a complete list, see Cluster Compatibility Matrix.
Before running a pipeline on a Hadoop YARN cluster, ensure all requirements are met. Before running a pipeline on a MapR Hadoop YARN cluster, complete the prerequisite tasks.
When you configure a pipeline to run on a Hadoop YARN cluster, you configure the deployment mode used for the launched application. By default, Transformer uses the user who starts the pipeline as the proxy user to launch the Spark application and access files in the Hadoop system. If you enable Transformer to use Kerberos authentication or Hadoop impersonation, you can override the default proxy user that launches the Spark application.
The following image displays a pipeline configured to run on Spark deployed to a Hadoop YARN cluster:
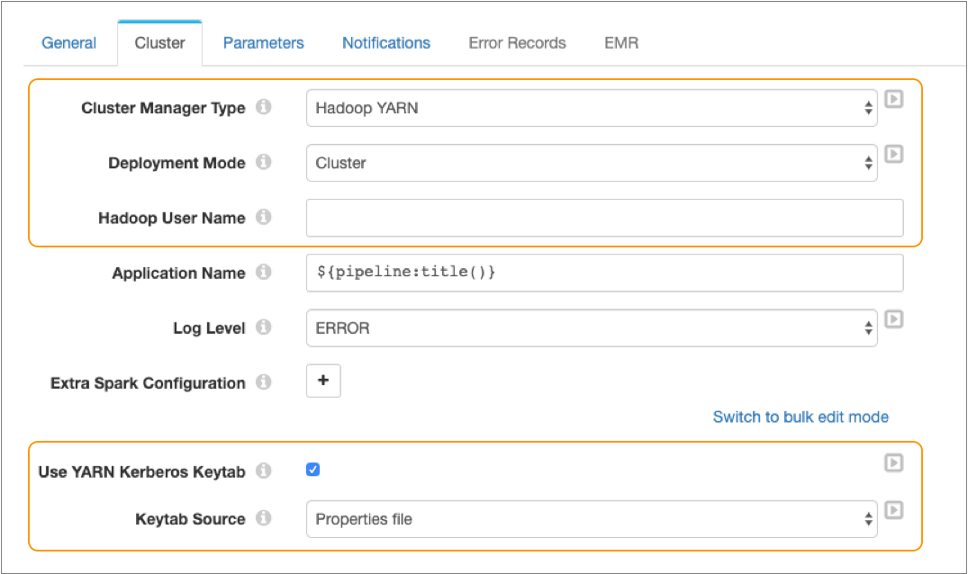
Notice how this pipeline is configured to run in cluster deployment mode. The Hadoop user name is not defined because the pipeline is configured to use Kerberos authentication.