Amazon EMR
You can run Transformer pipelines using Spark deployed on an Amazon EMR cluster. Transformer supports several EMR versions. For a complete list, see Cluster Compatibility Matrix.
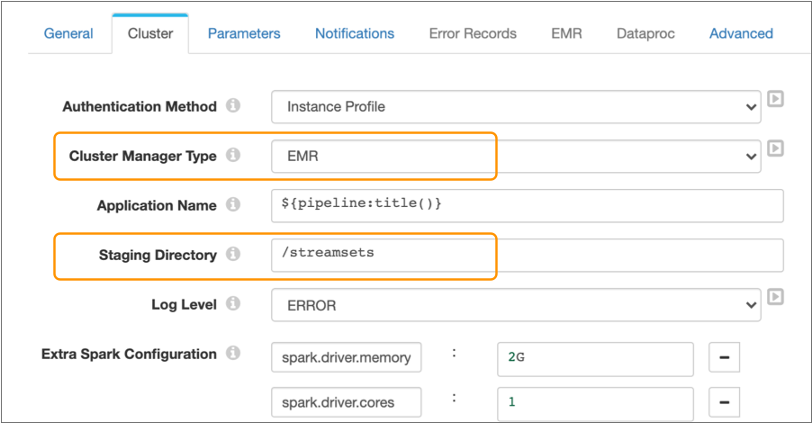
To run a pipeline on an EMR cluster, in the pipeline properties, you configure the pipeline to use EMR as the cluster manager type, then configure the cluster properties.
When you configure a pipeline to run on an EMR cluster, you can specify an existing Spark cluster to use or you can have Transformer provision a cluster to run the pipeline. When provisioning a cluster, you can optionally define bootstrap actions, enable logging, make the cluster visible to all users, and have Transformer terminate the cluster after the pipeline stops.
Terminating a provisioned cluster after the stops is a cost-effective method of running a Transformer . Running multiple on a single existing cluster can also reduce costs.
You define an S3 staging URI and a staging directory within the cluster to store the Transformer libraries and resources needed to run the pipeline.
You can configure the pipeline to use an instance profile or AWS access keys to authenticate with the EMR cluster. When you start the pipeline, Transformer uses the specified instance profile or AWS access key to launch the Spark application. You can also configure server-side encryption for data stored in the staging directory.
You can also use a connectionconnectionconnection to configure the pipeline.
The following image shows the Cluster tab of a pipeline configured to run on an EMR cluster: