Google Dataproc
You can run Transformer pipelines using Spark deployed on a Google Dataproc cluster. Transformer supports several Dataproc versions. For a complete list, see Cluster Compatibility Matrix.
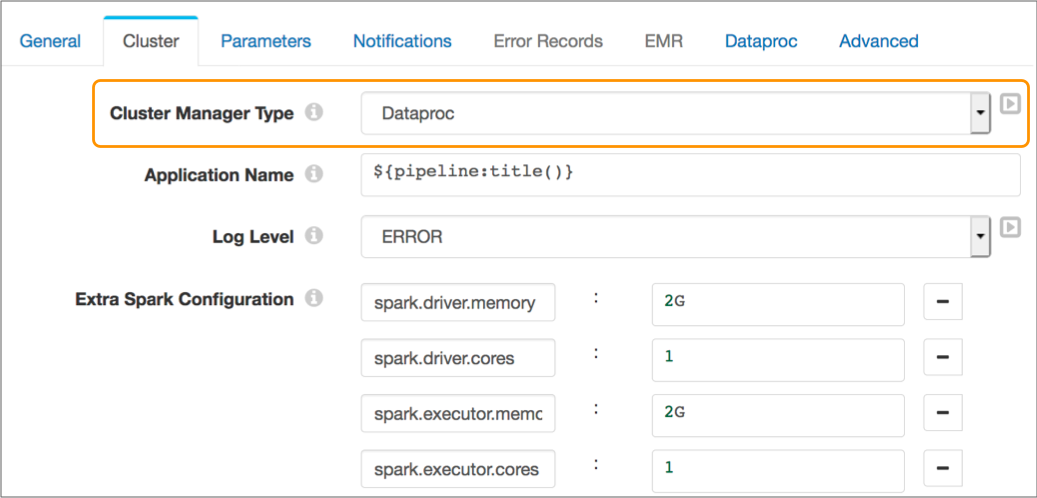
To run a pipeline on a Dataproc cluster, configure the pipeline to use Dataproc as the cluster manager type on the Cluster tab of the pipeline properties.
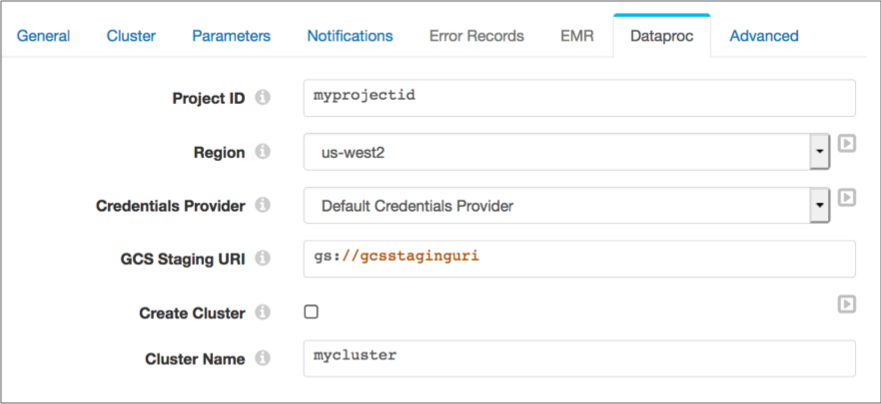
When you configure a pipeline to run on a Dataproc cluster, you specify the Google Cloud project ID and region, and the credentials provider and related properties. You define the staging URI within Google Cloud to store the StreamSets libraries and resources needed to run the pipeline.
You can specify an existing cluster to use or you can have Transformer provision a cluster to run the pipeline.
The following image shows the Cluster tab of a pipeline configured to run on a Dataproc cluster:
The following image shows the Dataproc tab configured to run the pipeline on an existing Dataproc cluster: