Databricks
You can run Transformer pipelines using Spark deployed on a Databricks cluster. Transformer supports several Databricks versions. For a complete list, see Cluster Compatibility Matrix.
To run a pipeline on a Databricks cluster, configure the pipeline to use Databricks as the cluster manager type on the Cluster tab of pipeline properties.
Transformer uses the Databricks REST API to perform tasks on Databricks clusters, such as submitting an ephemeral Databricks job to run the pipeline. Databricks retains details about ephemeral jobs for 60 days. When necessary, access job details while they are available.
When you configure a pipeline to run on a Databricks cluster, you can specify an existing interactive cluster to use or you can have Transformer provision a job cluster to run the pipeline.
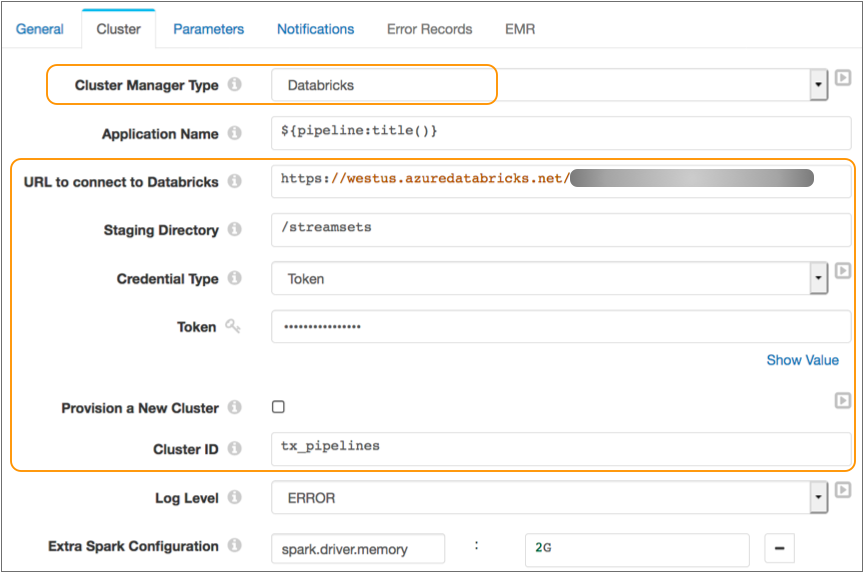
For both interactive and provisioned clusters, you define the staging directory within the Databricks File System (DBFS) to store the StreamSets libraries and resources needed to run the pipeline. You also specify the URL and credentials used to connect to your Databricks account. When you start a pipeline, Transformer uses these credentials to launch the Spark application.
The following image displays a pipeline configured to run on Spark deployed to an existing Databricks cluster on Microsoft Azure: