JDBC Tee
Supported pipeline types:
|
Use the JDBC Tee processor to write some or all record fields to a database table and then enrich records with additional data.
To use the processor, the database table must be configured to generate column values as data is inserted.
When you configure the JDBC Tee processor, you specify connection information to the MySQL or PostgreSQL database, table name, and optionally define field mappings. By default, the processor writes data to the table based on the matching field names. You can override the default field mappings by defining specific mappings.
You define generated column mappings to specify the output fields to pass the generated database column values to.
You can configure the stage to rollback an entire batch if an error occurs while writing part of the batch. You can also configure custom properties that your driver requires.
The JDBC Tee processor can use CRUD operations defined in the
sdc.operation.type record header attribute to write
data. You can define a default operation for records without the header
attribute or value. You can also configure whether to use multi-row
operations for inserts and deletes, and how to handle records with
unsupported operations.
You can specify the format of the change data capture log used to process data from a CDC-enabled origin. For information about Data Collector change data processing and a list of CDC-enabled origins, see Processing Changed Data.
To use a JDBC version older than 4.0, you can specify the driver class name and define a health check query.
You can also use a connectionconnectionconnection to configure the processor.
Example
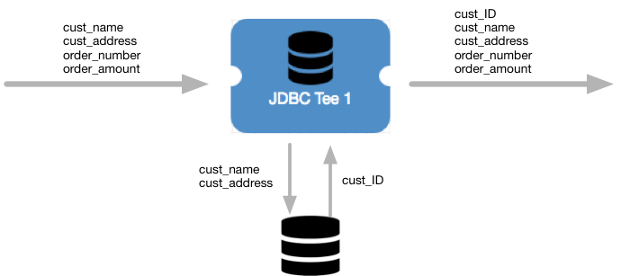
Let's assume that you are processing customer orders. You have a customer database
table with an ID column as the primary key. The customer table is
configured to generate a sequential number for the ID column as
each row is inserted into the table. For example, the first customer row is assigned
an ID of 001, and the second is assigned an ID of
002.
When you process a new customer’s order, the JDBC Tee processor inserts the customer
data to the customer table and the database returns the generated ID for that
customer. The JDBC Tee processor passes the generated ID value to a new
cust_ID field in the record. The processor passes all record
fields to the next stage in the pipeline for additional processing.
The following image displays a high-level overview of how the stage processes our customer order example: