Azure Synapse SQL
Supported pipeline types:
|
To load data, the destination first stages the pipeline data in CSV files in a staging area, either Azure Blob Storage or Azure Data Lake Storage Gen2. Then, the destination executes a COPY command to bulk load the staged data into Azure Synapse.
The following image displays the steps that the destination completes to load the data:
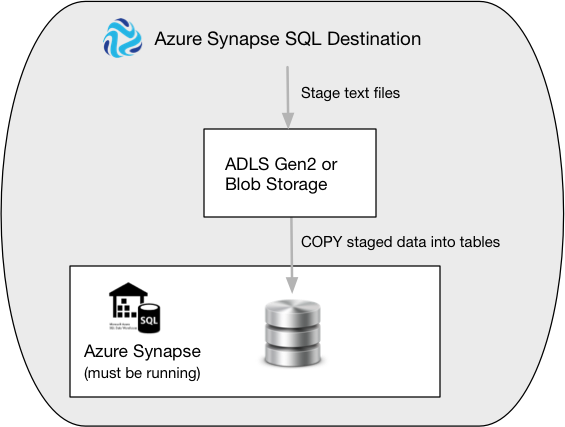
When you configure the Azure Synapse SQL destination, you specify authentication information for your Azure Synapse instance and for your Azure staging area. When needed, you can also specify copy statement authentication details for bulk loading to Azure Synapse.
You specify the name of the schema and tables to load the data into. The destination writes data from record fields to table columns based on matching names.
You can configure the destination to compensate for data drift by creating new columns in existing database tables when new fields appear in records or by creating new database tables as needed. When creating new tables, you can specify a partition column and partition boundary values to use.
You can configure the root field for the row, and any first-level fields that you want to exclude from the record. You can specify characters to represent null values.
You can configure the destination to replace missing fields or fields with invalid data types with user-defined default values. You can also configure the destination to replace newline characters and trim leading and trailing spaces.
Before you use the Azure Synapse SQL destination, you must complete some prerequisite tasks. The destination is available in the Azure Synapse Enterprise stage library. install the Azure Synapse stage library and complete other prerequisite tasks. The Azure Synapse stage library is an Enterprise stage libraryEnterprise stage library. Releases of Enterprise stage libraries occur separately from Data Collector releases. For more information, see Enterprise Stage Libraries in the Data Collector documentation.