Reading from Amazon S3
The Hadoop FS origin included in a cluster batch or cluster EMR batch pipeline allows you to read from Amazon S3.
To
read from Amazon S3, specify the appropriate URI for Amazon S3 when you configure the
Hadoop FS origin. Use the s3a scheme in the URI. S3A is the active
connector maintained by open source Hadoop and is the only connector that works with
Hadoop and Amazon S3.
Configure the URI to point to the Amazon S3 bucket to read from, as follows:
s3a://<bucket>s3a://WebServerThen in the Input Paths property, enter the full path to the data to be read within that Amazon S3 bucket. You can enter multiple paths for the Input Paths property, as follows:
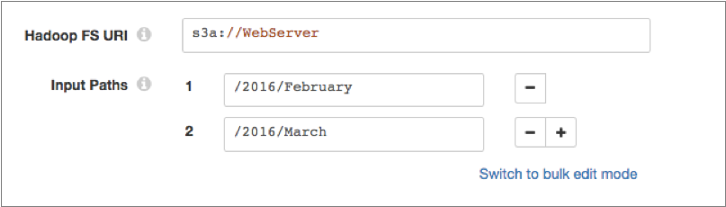
For additional requirements when using the Hadoop FS origin to read from Amazon S3, see Amazon S3 Requirements.